Vogelek23 napisał(a):motor kosiarki
- masz coś takiego w dyskach twardych? Mocno naciągana analogia do jednak zupełnie innej konstrukcji.
Vogelek23 napisał(a):łożyskowanie silnika ulega degradacji.
przy łożyskowaniu hydrodynamicznym zjawisko pomijalne. Bardzo trudno spotkać dysk, w jakim mechanicznemu uszkodzeniu uległby silnik. W dodatku z powodu naturalnego zużycia, a nie zewnętrznego przyłożenia siły. Z bardzo wysokim prawdopodobieństwem dysk zdechnie wcześniej z zupełnie innego powodu.
Vogelek23 napisał(a):producenci określają ją parametrem MTBF
- o tym, jak bzdurny jest to parametr, przekonasz się przeliczając podawane przez producentów godziny na lata. Ten czas jest obliczany w dość specyficzny sposób i na tendencyjnie dobranym zbiorze danych, w ogóle pomijając to, co się dzieje w okresie pogwarancyjnym. Nie wspominając o tym, że wartości podawane z dokładnością do setek tysięcy godzin już tylko przez to sprawiają wrażenie rzuconych "od czapy".
Vogelek23 napisał(a):ktoś oszacował uśrednioną żywotność
- nie będę kwestionował tego oszacowania - zbyt wiele wysiłku kosztowałoby mnie zebranie danych statystycznych, jakimi od ręki nie dysponuję, a jakaś średnia zawsze wyjdzie. Lepiej zastanówmy się, z czego ta średnia wynika. Np. z fabrycznych wad wykonawczych, jakie powodują, że jakiś mały odsetek dysków wysypuje się w pierwszych dniach eksploatacji, z czynników środowiska pracy (zasilanie, temperatury, wibracje, wilgotność...), zdarzeń losowych (upadki, uderzenia, wstrząsy - zdecydowana większość uszkodzeń mechanicznych wynika własnie z takich zdarzeń, usterki wynikające typowo z zużycia są naprawdę rzadkie), być może (nie znam metodologii autora oszacowania) też z wycofania sprawnych dysków z eksploatacji z powodów ekonomicznych (wymiana na SSD, wymiana całych komputerów, celowe zniszczenie dla zniszczenia danych zgodnie z jakimiś procedurami, czy też inny powód, kiedy dysk technicznie wciąż mógłby dalej pracować). Dlatego ta średnia siłą rzeczy będzie mocno zaniżona względem faktycznych możliwości eksploatacji dysku, jakiemu nic złego się nie przytrafiło. Zwróć uwagę, że wymieniając prawdopodobnie sprawny dysk tylko z powodu wypracowanych "motogodzin" też tę średnią zaniżasz, bo nie wiesz, czy ten dysk nie pociągnie drugie tyle, ale podejmujesz decyzję o prewencyjnej wymianie. Taka polityka często jest realizowana w centrach danych, gdzie duża ilość dysków jest wymieniana po upływie okresu gwarancji tylko dlatego, że skończyłaby się im gwarancja. I te dyski zazwyczaj są niszczone ze względu na polityki ochrony danych. I tego typu sytuacje bardzo mocno podważają sens sugerowania się jakimiś średnimi wartościami abstrahując od stanu technicznego konkretnego dysku.
Tak - co do SSDków kluczowe znaczenie ma sposób eksploatacji - m. in. ze względu na zużycie operacjami zapisu/kasowania nie nadają się do monitoringu, czy kopania kryptowaluty Chia (intensywne kopanie zabija SSDka zapisami w okresie kilku tygodni, góra - paru miesięcy). I dużym problemem są układy niskiej jakości w najtańszych modelach. Często wytrzymują one zaledwie ok. 600 cykli P/E. Dlatego swoim klientom zwykle rekomenduję te same modele, co i Ty, choć czasem muszę tłumaczyć, czemu 2x tańszy dysk o podobnych na papierze parametrach nie jest dobrym wyborem:)
W iMacach faktycznie spotkałem się z problemem przegrzewania się dysków. Co ciekawe - te dyski wyciągnięte i podłączone do innego komputera były normalnie rozpoznawane, nie grzały się, można było wykonać kopię posektorową. Nie umiem jednoznacznie odpowiedzieć na ile było to związane z problemem z odprowadzaniem ciepła, a na ile z jakąś trudno uchwytną niestabilnością zasilania. Niespecjalnie miałem okazję się doktoryzować na tym temacie, bo klienci zwykle chcą jak najszybciej odebrać swój sprzęt, więc najczęściej rozwiązywało się problem doraźnie czyszczeniem, a często też klonowaniem dysku i jego wymianą na nowy. Przy czym nowy w perspektywie 2-3 lat znowu zaczynał się grzać, a stary często pracował normalnie w jakichś innych zastosowaniach. Przynajmniej w przypadku stałych klientów, bo tylko u nich miałem późniejszą informację zwrotną. W każdym razie miałem tego za mało i za mało przy tym posiedziałem, żeby poza potwierdzeniem obserwacji takiego zjawiska, porwać się na dokładne wyjaśnienie jego przyczyn. Jeśli miałbym postawić u bukmachera, postawiłbym na problem z odprowadzaniem ciepła, jaki się relatywnie często zdarza i w innych komputerach typu All-in-one.
Jaki wpływ może mieć ciepło na możliwość zamontowania partycji? Przyczyny szukałbym po stronie fluktuacji wysokości lotu głowicy nad powierzchnią. Jeśli głowica odleci za daleko, sygnał jest zbyt słaby i może się pojawić problem z jego dekodowaniem, jeśli jest zbyt blisko powierzchni - szum może powodować zbyt wiele błędów bitowych - w obu przypadkach jednak powinniśmy mieć błędy odczytu. I w obu problem powinien ustępować po równomiernym nagrzaniu dysku do temperatury ok. 30-40 stopni. Jeśli sektory się czytają poprawnie, a partycja nie chce się zamontować, problem najprawdopodobniej ma charakter logiczny/systemowy, a to już trudno powiązać z temperaturą dysku. Być może schładzając dysk zamontowany w iMacu chłodziłeś też i inne elementy?
Swoją drogą, mniej więcej w tym okresie producenci zaczęli umieszczać w dyskach rezystory pozwalające na regulację wysokości lotu głowicy przez termiczne odkształcanie ślizgaczy.
Vogelek23 napisał(a):W tym konkretnym przypadku partycje po wymianie głowic można było normalnie zamontować
- czy pamiętasz dokładnie, jak się zachowywał tamten dysk? Dyski z uszkodzonymi głowicami zazwyczaj mają problem z przechwyceniem sygnału serwo, nie potrafią odnaleźć ścieżek i wchodzą w stuk latając od ogranicznika do ogranicznika. Nie zawsze ten objaw oznacza, że są uszkodzone głowice, ale jest on bardzo typowy. Dysk, jaki jest poprawnie rozpoznawany i można z nim złapać jakąkolwiek komunikację, zazwyczaj głowice ma sprawne. A co najmniej ma sprawną głowicę systemową (typowo głowica 0) - czyli głowicę czytającą strefę serwisową. Czasem może się zdarzyć, że któraś inna głowica jest uszkodzona - to można zauważyć obserwując dużą liczbę uszkodzonych sektorów w określonych interwałach, jakie wynikają z liczby głowic w danym dysku i przypisanych poszczególnym powierzchniom adresów LBA. Jak dasz rady czytać po ukraińsku, zobacz to:
https://kaleron.edu.pl/vykorystannia-po ... danych.phpPolską wersję też zrobię, ale chyba nie w tym roku:)
W iMacach typowo były montowane Seagaty - w nich głowice można było sprawdzić w terminalu szeregowym poleceniem 7>X Z nowszymi jest problem, bo od kilku lat obsługa terminalu szeregowego jest zablokowana i trzeba ingerować w EEPROM.
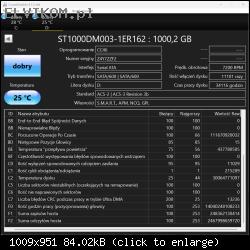
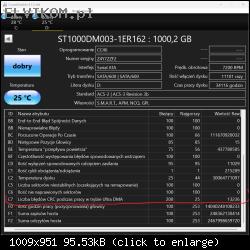
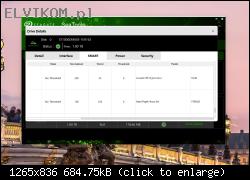
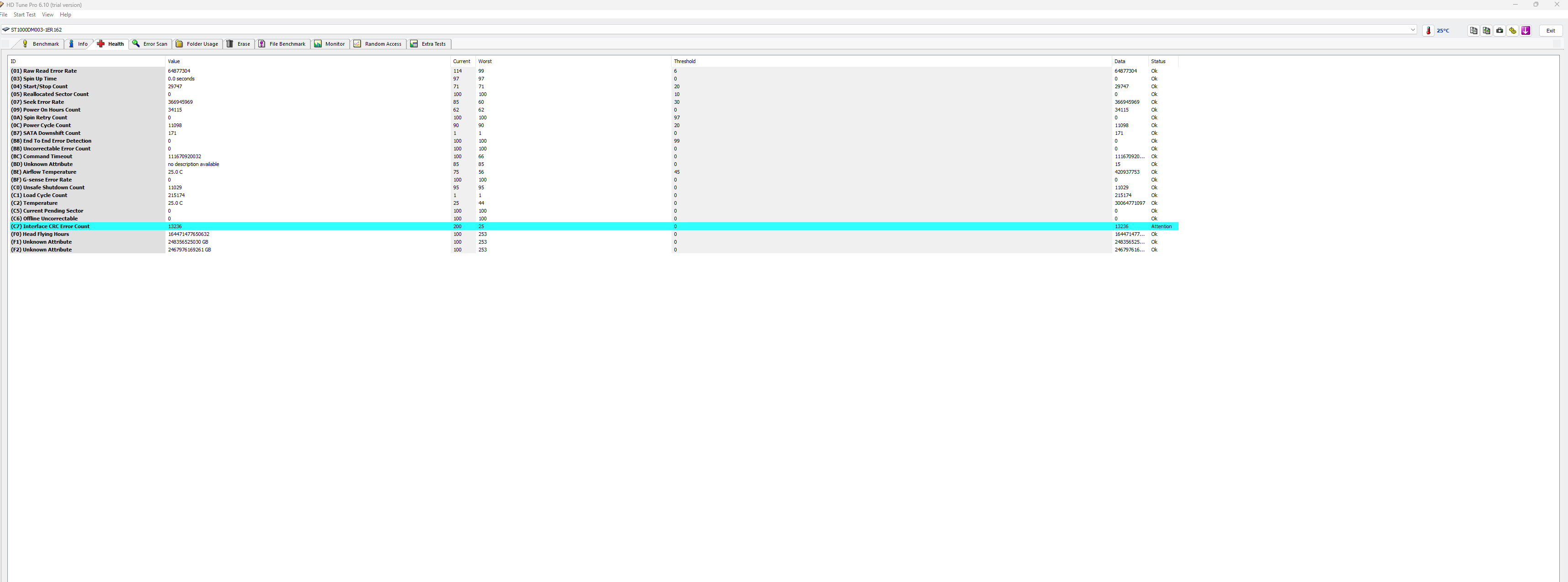
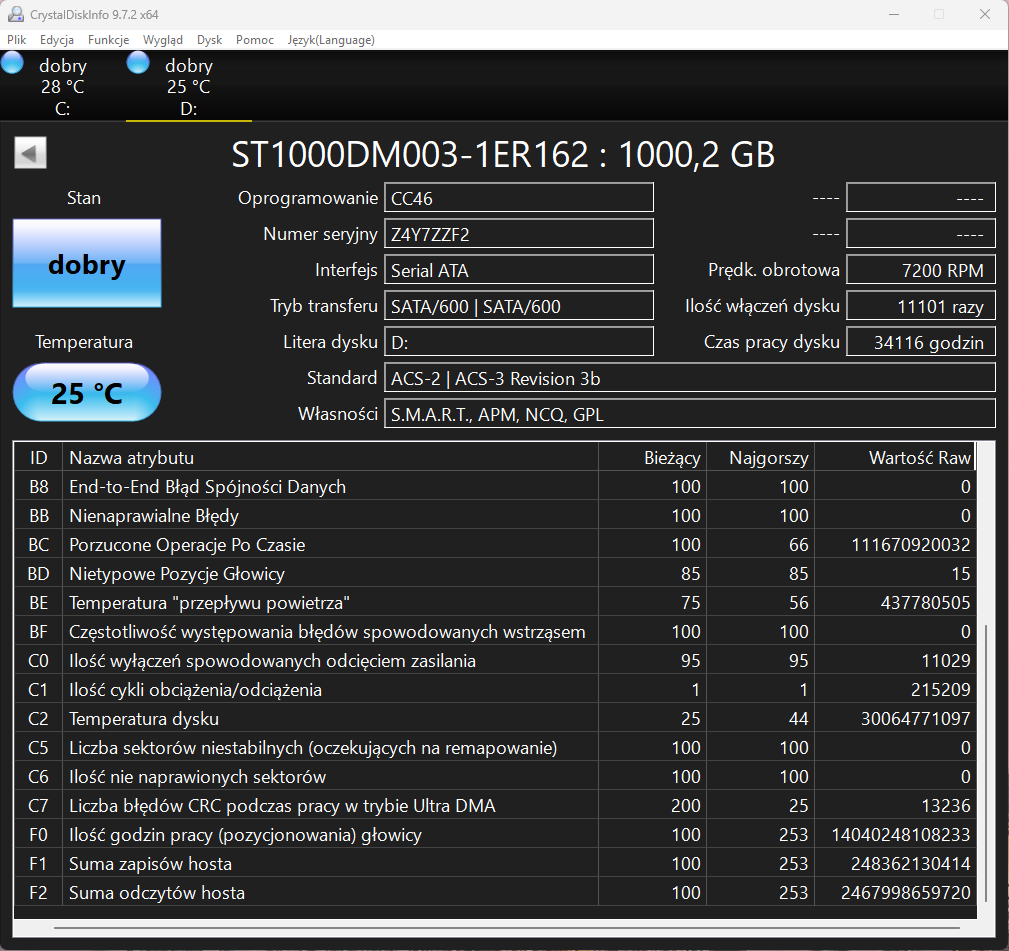
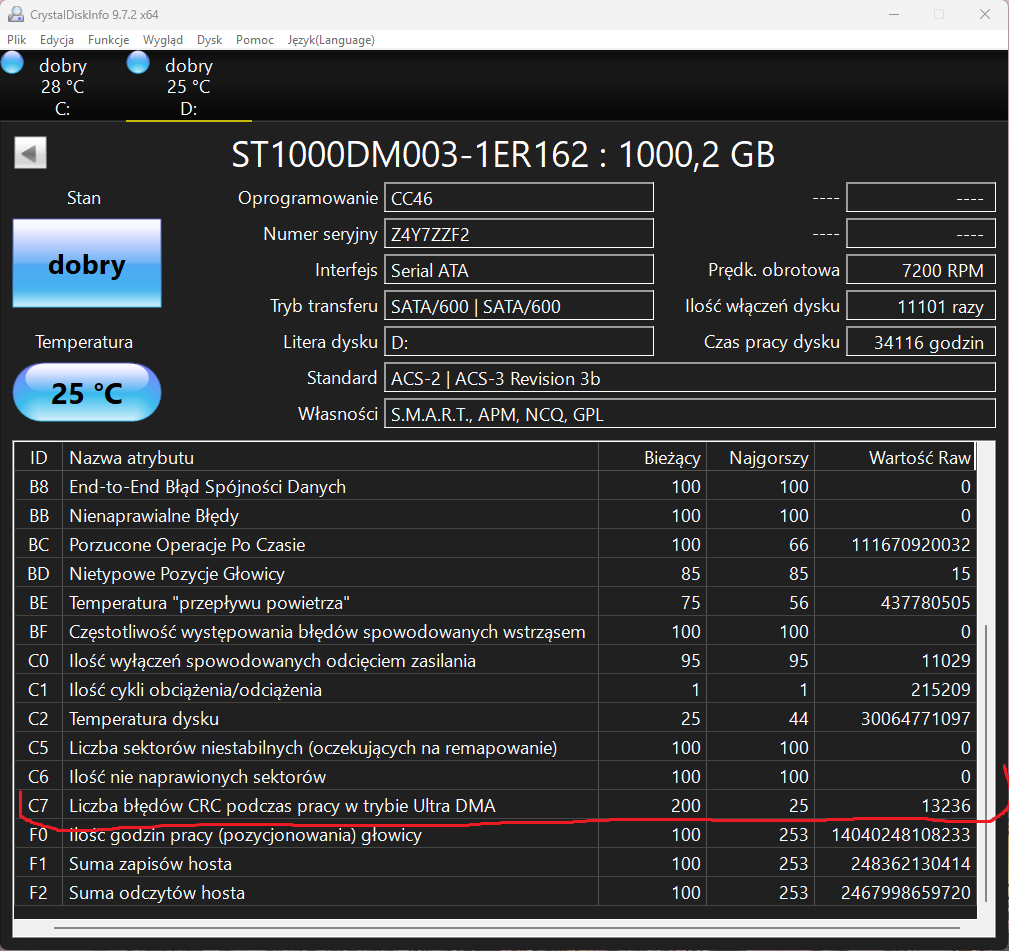
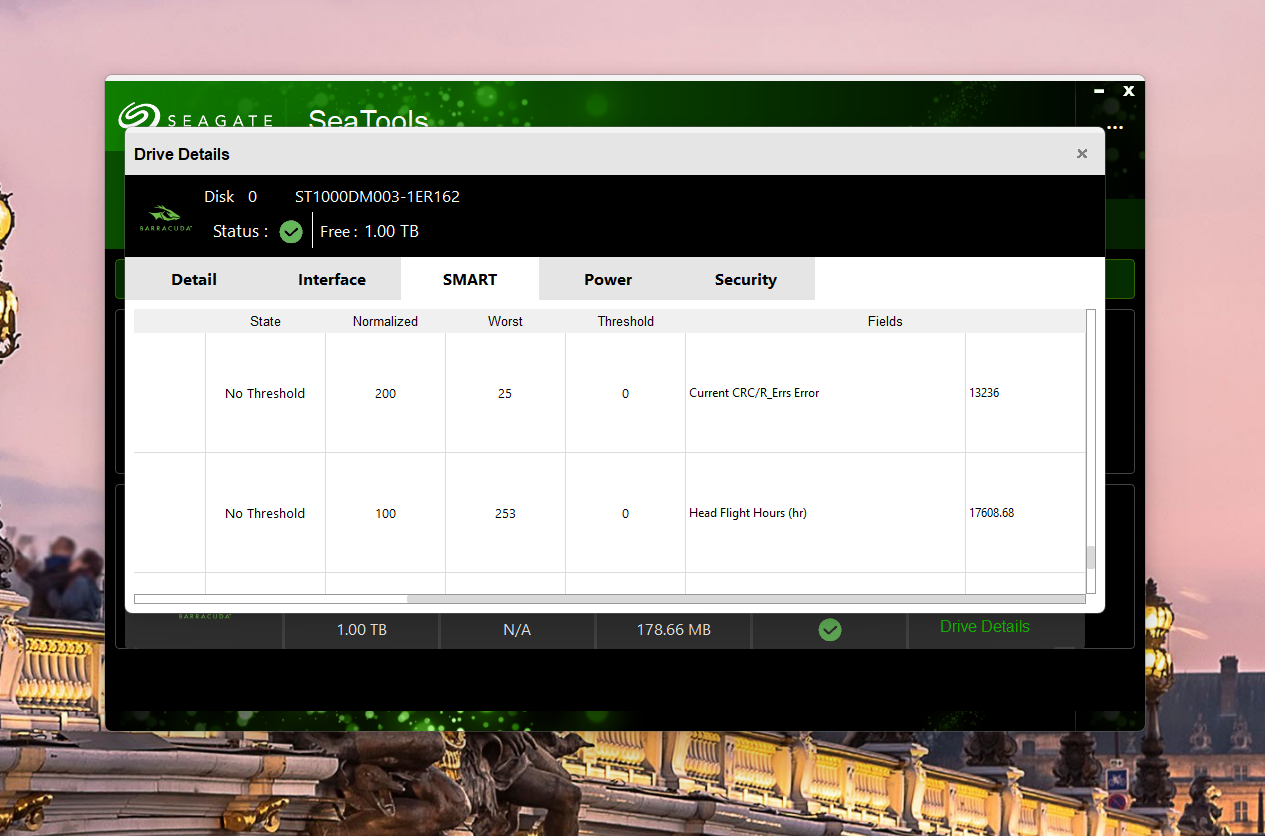
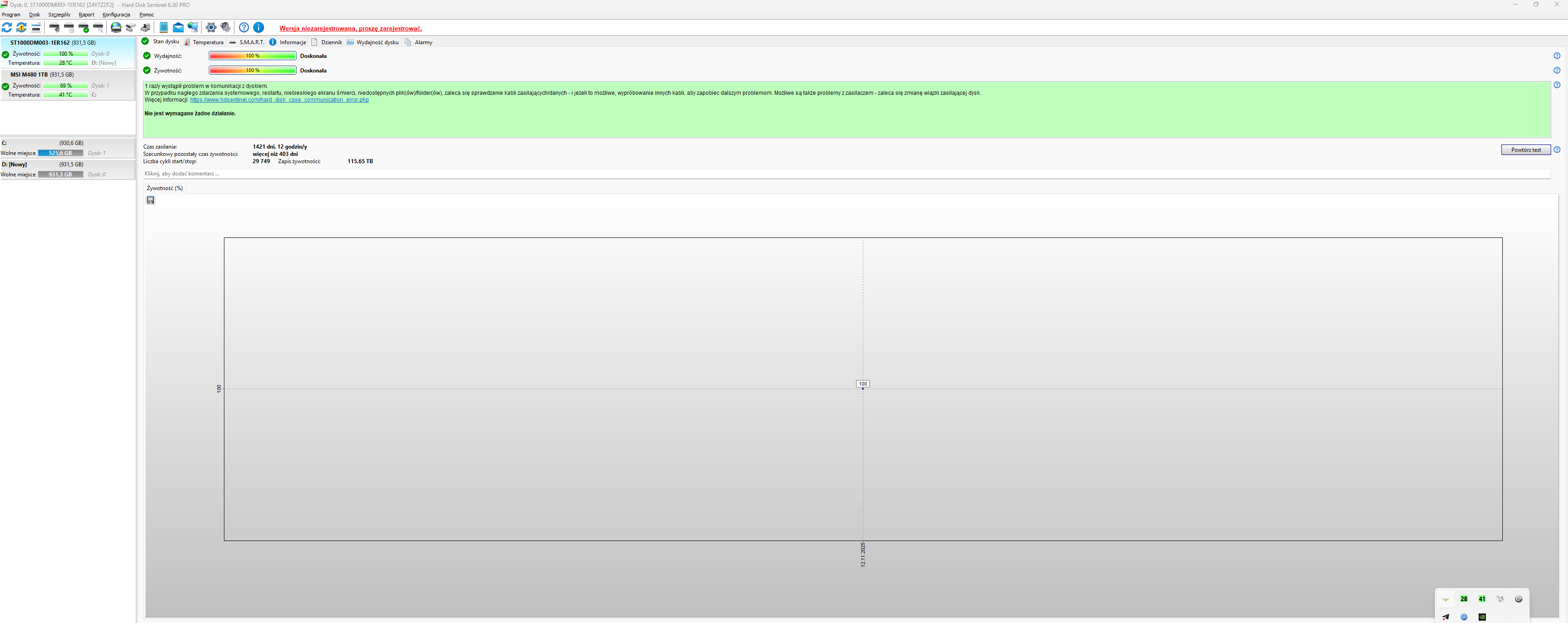
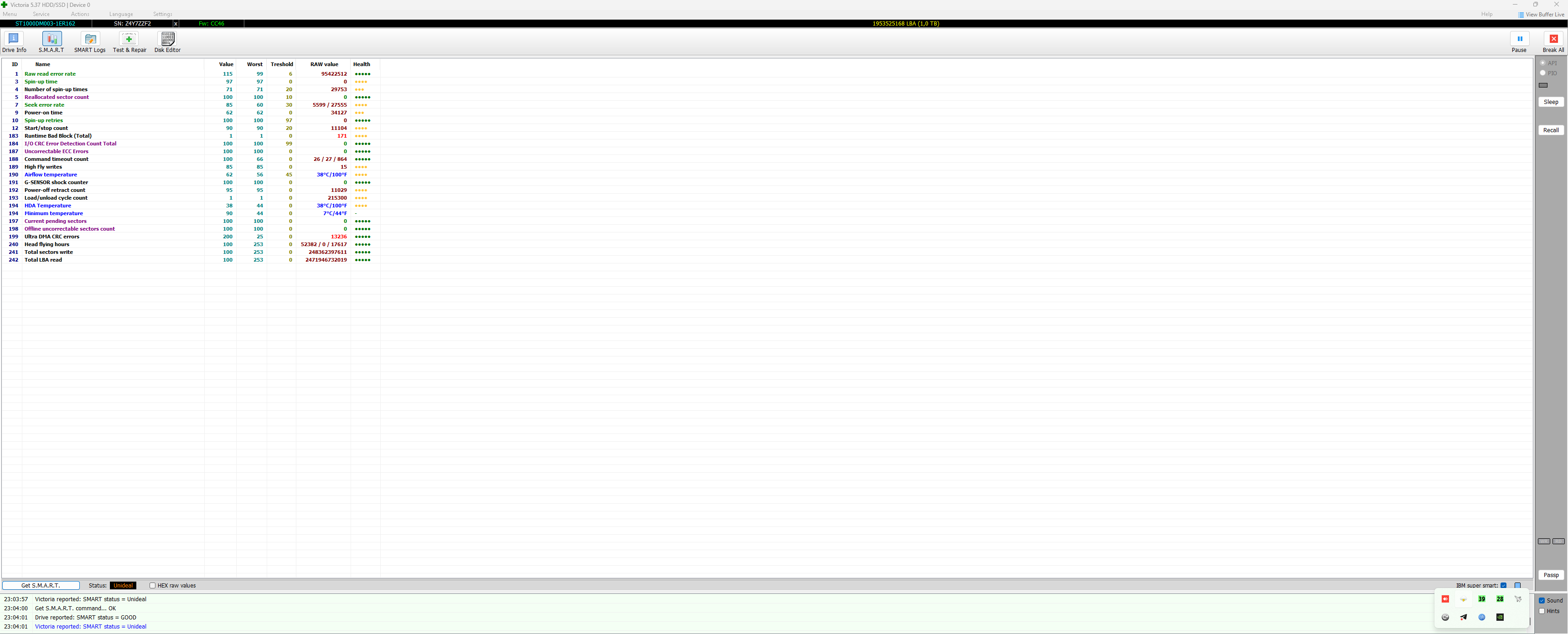
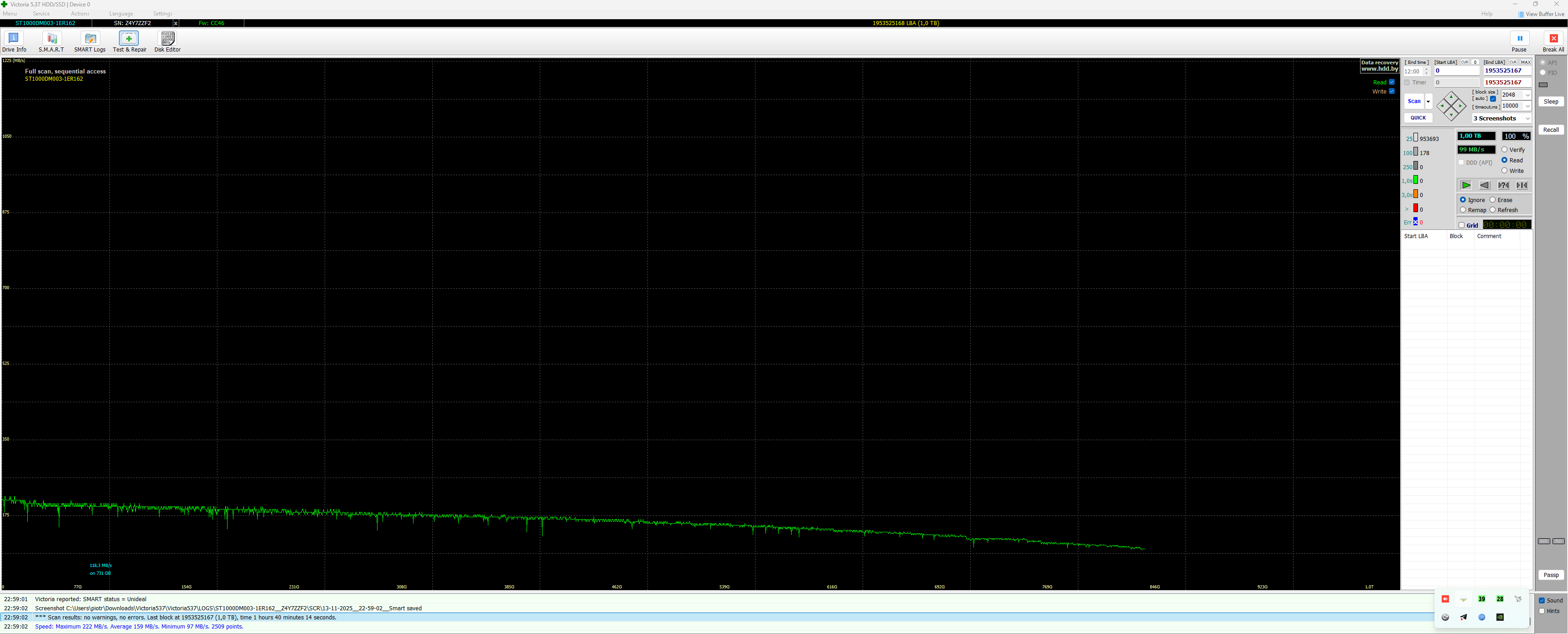
Bez szczegółowej diagnostyki Twojego dysku trudno mi odpowiedzieć, na ile wymiana głowic była uzasadniona, a na ile była zbędnym ryzykiem, a dane udało Ci się odzyskać "przypadkiem". W przypadku dysku Autora tematu, nie widzę żadnych wskazań, by typować problem z głowicami. Być może w toku dalszej diagnostyki takie wskazania się pojawią, ale na ten moment się ich nie spodziewam. Biorąc pod uwagę dobry wynik skanu, jest to skrajnie nieprawdopodobne.
Vogelek23 napisał(a):Przed wymianą głowic dysk "rozłączał się" podczas wykonywania kopii w losowych momentach,
- cały czas trzymając się założenia, że mówimy o jakimś Seagacie - w takiej sytuacji warto ustalić, z jakim błędem mamy do czynienia. Być może to rozłączanie dysku nie było losowe. Seagaty mają taki problem, że przy degradacji powierzchni w pewnym momencie przestają odpowiadać na polecenia (błąd ABRT przy próbie odczytania dowolnego sektora, w tym takich, jakie jeszcze przed chwilą przeczytały się poprawnie), a po zresetowaniu dysku zachowują się normalnie. Z tym problemem można walczyć wyłączając procesy w tle - polecenia terminalu szeregowego"
T>F"RWRecoveryFlags",00,22
T>F"BGMSFlags",00,22
T>F"PerformanceFlags",0060,22
Przy czym jeśli dysk by się zawieszał, możesz też spróbować
T>F"RWRecoveryFlags",01,22
i klonować ile się da, normalnie, a potem z kopią wsteczną do miejsc, gdzie zaczyna rzucać ABRTami, często też manualnie zawężając zakresy adresów LBA, jeśli takich problematycznych miejsc jest więcej.
Ale to hipoteza, bo tamten dysk nie był sprawdzony pod kątem tej przyczyny problemu.
Czasem problem w wewnętrznej komunikacji dysku wynika z utlenienia/zasiarczenia/ zaśniedzenia złącza między PCB, a blokiem głowic - odczyszczenie tego złącza nieraz potrafi pomóc.
Dyski i ich usterki ogólnie zasługują na lepsze zbadanie i opisanie, ale kto ma na to dość czasu:)